
#RStats — Text mining with R and gutenbergr
Introduction to text-mining with R and gutenbergr.
What is text-mining ?
At the crossroads of linguistics, computer science and statistics, text-mining is a data-mining technic used to analyze a corpus, in order to discover patterns, trends and singularities in a large number of texts. For example, you can analyse the Twitter description of your followers, or even get information from 5000 Facebook statuses, etc. Pretty cool, right?
The first “step” is perhaps the simplest to understand : frequency analysis. As the name suggests, this technique calculates the recurrence of each word inside a corpus — in other words… their frequency. This allows you to compare several texts. As an example, let’s assume you’re analysing 2500 comments on the Facebook page of your favorite brand / city / star, and find that among the most frequent words are “thank you”, “beautiful”, “super”. If you take two competing brands / cities / stars, you come across “yeurk” and “hate” on one, and “disgusting” and “catastrophic” on the other… pretty straightforward, isn’t it?
gutenbergr
I’ve chosen to analyse Lewis Caroll’s famous masterpiece, Alice’s Adventures in Wonderland. Why? I could have selected the last 1500 Tweets containing #Rennes … but:
- That has been done before
- Good literature has never hurt anyone :)
gutenbergr is an R package you can use to dowload books from the Gutenberg Project.
library(gutenbergr)
aliceref <- gutenberg_works(title == "Alice's Adventures in Wonderland")
This function gives you a list with the following elements:
## [1] "gutenberg_id" "title" "author"
## [4] "gutenberg_author_id" "language" "gutenberg_bookshelf"
## [7] "rights" "has_text"
The first column contains the reference of the book you’re looking for in the Gutenberg catalogue. You need this number to download the book:
library(magrittr)
alice <- gutenberg_download(aliceref$gutenberg_id) %>% gutenberg_strip()
Here, gutenberg_download takes the ID of the book you want to download, and returns you a data.frame with the full text. gutenberg_strip removes all the metadata at the beginning of the book.
Alice’s Adventures in Wonderland
library(tidytext)
To perform your data analysis, you’ll need the tidytext package. Then :
tidytext <- data_frame(line = 1:nrow(alice), text = alice$text) %>%
unnest_tokens(word, text) %>%
anti_join(stop_words) %>%
count(word, sort = TRUE)
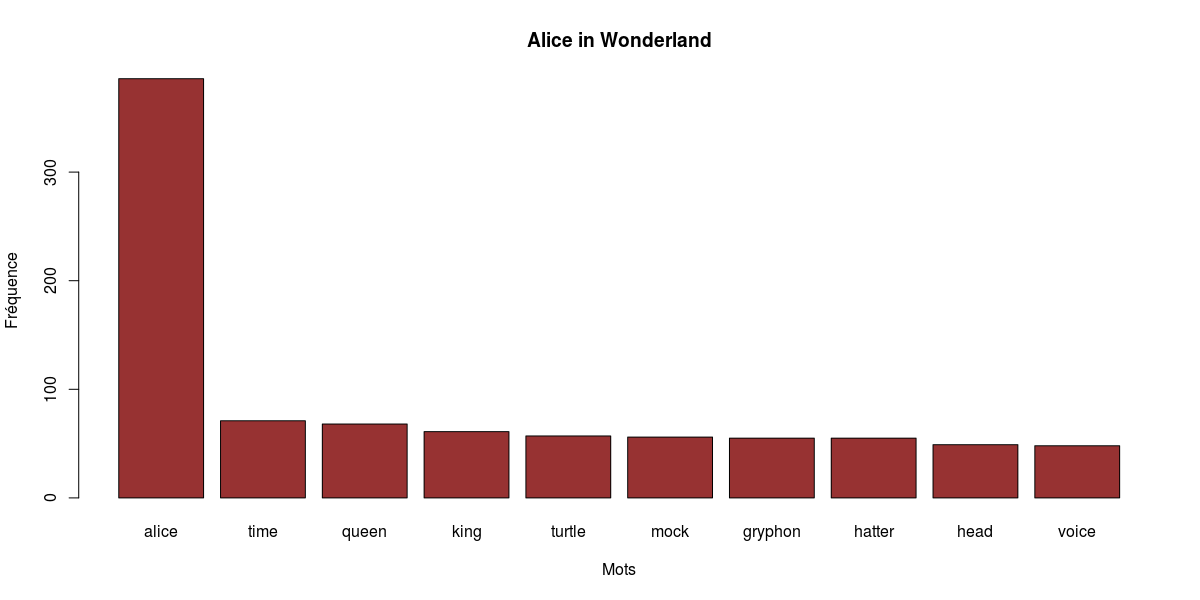
barplot(height=head(tidytext,10)$n, names.arg=head(tidytext,10)$word, xlab="Mots", ylab="Fréquence", col="#973232", main="Alice in Wonderland")
Perfect! So…drum rolls…
Further reading (in french) :
Racinisation et lemmatisation avec R
Read more :
Text Mining With R: A Tidy Approach
Text Mining: A Guidebook for the Social Sciences
Mining Text Data
Text Mining
Mastering Text Mining with R
Text Mining in Practice With R
Text Mining: From Ontology Learning to Automated Text Processing Applications
Text Mining: Classification, Clustering, and Applications
Phrase Mining from Massive Text and Its Applications
Text Mining: Applications and Theory
What do you think?