
#RStats — Text mining avec R et gutenbergr
Technique de data-mining et Graal des temps modernes, la fouille de texte permet de faire émerger des informations depuis un large corpus. Comment le réaliser avec R ?
Le text-mining, qu’est-ce que c’est
Au croisement de la linguistique, de l’informatique et des statistiques, le text-mining est utilisé pour analyser un corpus de manière automatique. L’objectif (au-delà de faire le malin devant vos collègues) : faire émerger des patterns, des tendances et des singularités depuis une quantité importante de textes. Par exemple, le text-mining vous permettra de tirer des informations de la description Twitter de vos 1500 followers, ou encore de 5000 statuts Facebook… Pretty cool, right?
La première étape du text-mining, et peut-être la plus simple à saisir : l’analyse de fréquence. Comme son nom l’indique, cette technique calcule la récurrence des mots dans un corpus — en d’autres termes, leur fréquence d’apparition. En pratique, cela vous permet de comparer deux corpus afin d’en tirer des conclusions… Un exemple ? Imaginez que vous analysiez les 2500 derniers commentaires sous la page Facebook de votre marque/ville/star préférée, et que vous découvriez que parmi les mots les plus fréquents se trouvent “merci”, “magnifique”, “super”. Si vous prenez deux marques/villes/stars concurrentes, vous tombez sur “bif-bof” et “moyen” sur l’une, “dégueu”, “beurk” et “catastrophique” sur l’autre… On peut en déduire quelque chose, n’est-il pas ?
gutenbergr
Pour cette démonstration, j’ai choisi de m’intéresser au célèbre chef-d’oeuvre de Lewis Caroll, Alice’s Adventures in Wonderland. Pourquoi ce texte ? En effet, j’aurais pu sélectionner les 1500 derniers Tweets contenant le hashtag Rennes… mais :
- D’autres l’ont fait avant nous
- Un peu de vraie littérature, ça fait parfois du bien, non ? (Twittos, rassurez-vous : je vous aime)
Bref, retour à nos moutons. Déposé sur le CRAN le 16 mai 2016, gutenbergr permet de télécharger des ouvrages du domaine public sur le Projet Gutenberg, une bibliothèque de livres électroniques libres de droits.
library(gutenbergr)
aliceref <- gutenberg_works(title == "Alice's Adventures in Wonderland")
Cette première fonction vous retourne un objet contenant les informations sur une oeuvre déposée sur le projet Gutenberg, avec les données suivantes :
## [1] "gutenberg_id" "title" "author"
## [4] "gutenberg_author_id" "language" "gutenberg_bookshelf"
## [7] "rights" "has_text"
La première colonne, contenant le 11, vous renvoie la référence de l’ouvrage sur le catalogue du projet : une information qui vous sera indispensable à la requête suivante :
library(magrittr)
alice <- gutenberg_download(aliceref$gutenberg_id) %>% gutenberg_strip()
Ici, gutenberg_download prend comme argument l’ID de l’ouvrage que vous souhaitez télécharger, vous renvoyant un data.frame avec le texte complet. La commande suivante gutenberg_strip retire les informations en haut et en bas de chaque éléments du projet : les métadonnées de l’ouvrage, que nous n’utiliserons pas pour l’analyse de fréquence.
Text-mining de Alice’s Adventures in Wonderland
library(tidytext)
Bon, passons maintenant aux choses sérieuses. Pour réaliser un text-mining, vous aurez besoin du package tidytext, intitulé ainsi pour son usage au text mining via la philosphie “tidy data”(pas bête, non ?).
tidytext <- data_frame(line = 1:nrow(alice), text = alice$text) %>%
unnest_tokens(word, text) %>%
anti_join(stop_words) %>%
count(word, sort = TRUE)
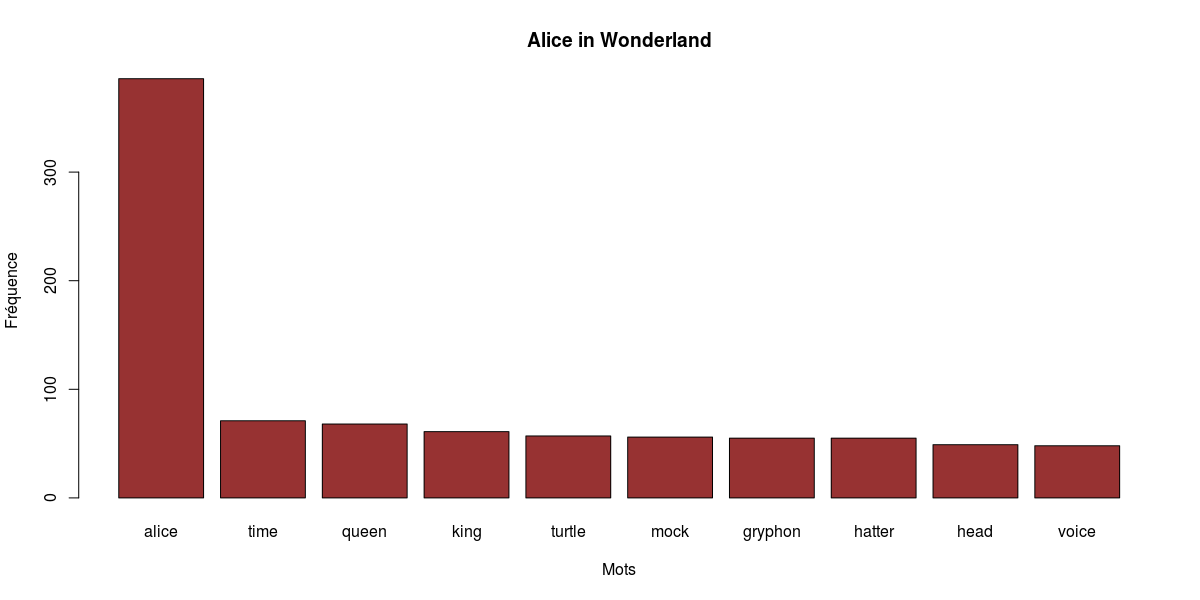
barplot(height=head(tidytext,10)$n, names.arg=head(tidytext,10)$word, xlab="Mots", ylab="Fréquence", col="#973232", main="Alice in Wonderland")
Alors… Roulement de tambour…
Pour aller plus loin :
Racinisation et lemmatisation avec R
En lire plus :
Text Mining With R: A Tidy Approach
Text Mining: A Guidebook for the Social Sciences
Mining Text Data
Text Mining
Mastering Text Mining with R
Text Mining in Practice With R
Text Mining: From Ontology Learning to Automated Text Processing Applications
Text Mining: Classification, Clustering, and Applications
Phrase Mining from Massive Text and Its Applications
Text Mining: Applications and Theory
What do you think?