
Data & Vinyles — Exploration d’une bibliothèque Discogs avec R
Amoureux de données et de vinyles, je me suis amusé à envoyer quelques requêtes sur l’API Discogs avec R, pour en savoir un peu plus sur ma collection.
Réseau social incontournable des amateurs du disque microsillon, Discogs offre une API permettant de jongler entre musique et données en quelques lignes de code.
Note : pour retrouver les données utilisées dans ce billet, vous pouvez télécharger le document JSON ici, ou directement dans R :
collection_complete <- jsonlite::fromJSON(txt = "http://colinfay.me/data/collection_complete.json", simplifyDataFrame = TRUE)
Major Tom to Discogs API
Avant de se lancer, chargeons dans l’environnement deux fonctions qui me seront indispensables : _%>% et %||%.
library(magrittr)
`%||%` <- function(a,b) if(is.null(a)) b else a
Bien bien, commençons par faire venir le profil Discogs :
user <- "_colin"
content <- httr::GET(paste0("https://api.discogs.com/users/", user, "/collection/folders"))
content <- rjson::fromJSON(rawToChar(content$content))$folders
content
## [[1]]
## [[1]]$count
## [1] 308
##
## [[1]]$resource_url
## [1] "https://api.discogs.com/users/_colin/collection/folders/0"
##
## [[1]]$id
## [1] 0
##
## [[1]]$name
## [1] "All"
Cette première requête nous permet d’obtenir les informations basiques sur l’utilisateur (en l’occurrence “_colin“, principal intéressé de ce billet de blog).
$count
``` nous apprend notamment que la collection compte 308 entrées. L’élément de la liste ```r
$id
``` renvoie le nombre de “folders” Discogs créées par l’utilisateur – ici, 0 correspond à l’ensemble de la collection, sans spécification de liste.
### Créer un data.frame avec l’ensemble des vinyles présents dans la collection
L’API Discogs permet d'accéder à des pages de 100 résultats maximum. Ma collection contenant 308 entrées, nous devons réaliser une boucle ```r
repeat
``` qui collectera l’ensemble des données, avant de créer un tableau final contenant l’ensemble de la collection.
```r
collec_url <- httr::GET(paste0("https://api.discogs.com/users/", user, "/collection/folders/", content[[1]]$id, "/releases?page=1&per_page=100"))
if (collec_url$status_code == 200){
collec <- rjson::fromJSON(rawToChar(collec_url$content))
collecdata <- collec$releases
if(!is.null(collec$pagination$urls$`next`)){
repeat{
url <- httr::GET(collec$pagination$urls$`next`)
collec <- rjson::fromJSON(rawToChar(url$content))
collecdata <- c(collecdata, collec$releases)
if(is.null(collec$pagination$urls$`next`)){
break
}
}
}
}
collection <- lapply(collecdata, function(obj){
data.frame(release_id = obj$basic_information$id %||% NA,
label = obj$basic_information$labels[[1]]$name %||% NA,
year = obj$basic_information$year %||% NA,
title = obj$basic_information$title %||% NA,
artist_name = obj$basic_information$artists[[1]]$name %||% NA,
artist_id = obj$basic_information$artists[[1]]$id %||% NA,
artist_resource_url = obj$basic_information$artists[[1]]$resource_url %||% NA,
format = obj$basic_information$formats[[1]]$name %||% NA,
resource_url = obj$basic_information$resource_url %||% NA)
}) %>% do.call(rbind, .) %>%
unique()
Et pour un aperçu du tableau obtenu :
library(pander)
pander(head(collection))
| release_id | label | year | title |
|---|---|---|---|
| 5181773 | A&M Records | 1982 | Night And Day |
| 3690646 | A&M Records (2) | 2012 | God Save The Queen |
| 944917 | Alexi Delano Limited | 2007 | The Acid Sessions Vol. 4 |
| 906983 | Alphabet City | 2007 | Urban Minds / Skattered |
| 8112758 | Amerilys | 1986 | Follement Vôtre |
| 5800664 | Anette Records | 2014 | And The Dead Shall Lie There |
| artist_name | artist_id | artist_resource_url | format |
|---|---|---|---|
| Joe Jackson | 75280 | https://api.discogs.com/artists/75280 | Vinyl |
| Sex Pistols | 31753 | https://api.discogs.com/artists/31753 | Vinyl |
| Alexi Delano | 26 | https://api.discogs.com/artists/26 | Vinyl |
| Pacjam | 488187 | https://api.discogs.com/artists/488187 | Vinyl |
| Diane Dufresne | 647100 | https://api.discogs.com/artists/647100 | Vinyl |
| Ancient Mith | 302464 | https://api.discogs.com/artists/302464 | Vinyl |
I can’t see, I can’t see I’m going blind
Bon, il est temps de mettre tout cela en forme, non ?
Les labels les plus représentés
library(ggplot2)
ggplot(as.data.frame(head(sort(table(collection$label), decreasing = TRUE), 10)), aes(x = reorder(Var1, Freq), y = Freq)) +
geom_bar(stat = "identity", fill = "#B79477") +
coord_flip() +
xlab("Label") +
ylab("Fréquence") +
ggtitle("Labels les plus fréquents")
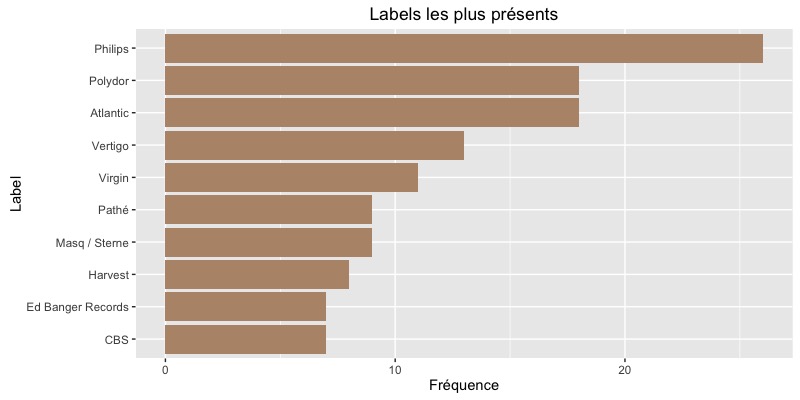
Philips et Polydor, what a surprise!
Les artistes les plus représentés
ggplot(as.data.frame(head(sort(table(collection$artist_name), decreasing = TRUE), 10)), aes(x = reorder(Var1, Freq), y = Freq)) +
geom_bar(stat = "identity", fill = "#B79477") +
coord_flip() +
xlab("Artistes") +
ylab("Fréquence") +
ggtitle("Artistes les plus fréquents")
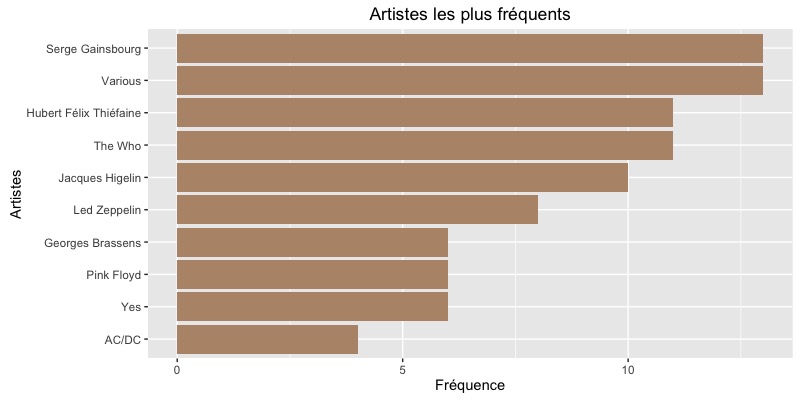
Bon, voilà, vous le savez… j’aime beaucoup Serge Gainsbourg et Georges Brassens (j’assume). La présence forte de Various était prévisible : il s’agit d’un terme générique faisant référence aux compilations, il est donc plus facile de gonfler ce chiffre que celui d’un artiste “solo”.
Date de sortie des vinyles de la collection
ggplot(dplyr::filter(collection, year != 0), aes(x = year)) +
geom_bar(stat = "count", fill = "#B79477") +
xlab("Année de sortie") +
ylab("Fréquence") +
ggtitle("Date de sorties des vinyles de la collection")
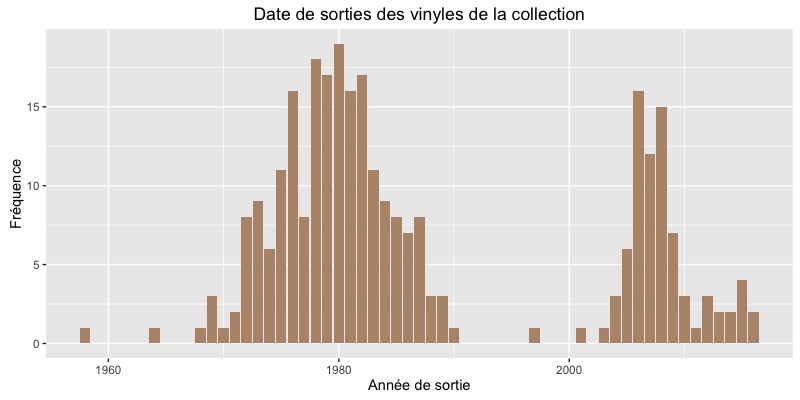
Woaw, j’ai comme l’impression que je ne suis pas un super fan des années 90… Pourtant, il y a de super titres, non ? Ma collection se concentre sur un gros pic autour des années 80 et 00, avec un mode en 1980.
It’s time to go deeper
Bien, ces infos un temps soit peu basiques nous offrent déjà une première vision des vinyles dans ma collection. Et si l’on allait plus loin ?
Hello, it’s me again
_Note: depuis l’écriture de cet article, Discogs semble avoir intégré une limitation au volume de calls par minute. Afin de créer collection_2, vous devez faire à Sys.sleep(). En savoir plus.
collection_2 <- lapply(as.list(collection$release_id), function(obj){
url <- httr::GET(paste0("https://api.discogs.com/releases/", obj))
url <- rjson::fromJSON(rawToChar(url$content))
data.frame(release_id = obj,
label = url$label[[1]]$name %||% NA,
year = url$year %||% NA,
title = url$title %||% NA,
artist_name = url$artist[[1]]$name %||% NA,
styles = url$styles[[1]] %||% NA,
genre = url$genre[[1]] %||% NA,
average_note = url$community$rating$average %||% NA,
votes = url$community$rating$count %||% NA,
want = url$community$want %||% NA,
have = url$community$have %||% NA,
lowest_price = url$lowest_price %||% NA,
country = url$country %||% NA)
}) %>% do.call(rbind, .) %>%
unique()
Ici, nous utilisons le release_id pour aller à la pêche aux informations pour toutes les entrées de la base.
Les genres les plus représentés
ggplot(as.data.frame(head(sort(table(collection_2$genre), decreasing = TRUE), 10)), aes(x = reorder(Var1, Freq), y = Freq)) +
geom_bar(stat = "identity", fill = "#B79477") +
coord_flip() +
xlab("Genre") +
ylab("Fréquence") +
ggtitle("Genres les plus fréquents")
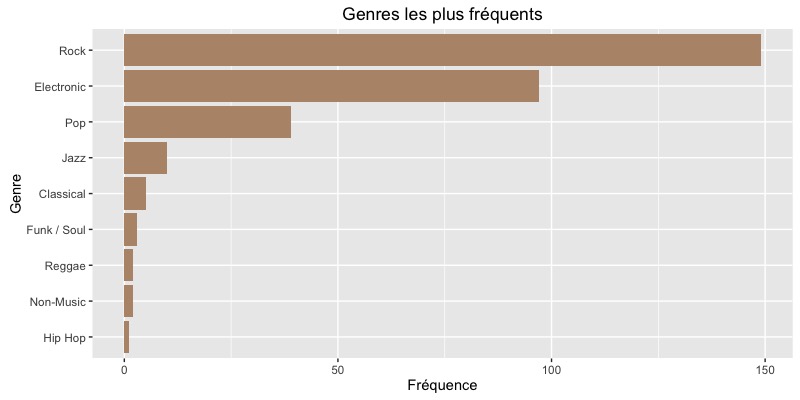 OH GOD, quelle surprise ! Eh oui, presque la moitié de ma collection contient des vinyles de rock (tous styles confondus). Qui aurait pu s’en douter ?
OH GOD, quelle surprise ! Eh oui, presque la moitié de ma collection contient des vinyles de rock (tous styles confondus). Qui aurait pu s’en douter ?
Pays d’origine des vinyles
ggplot(as.data.frame(head(sort(table(collection_2$country), decreasing = TRUE), 10)), aes(x = reorder(Var1, Freq), y = Freq)) +
geom_bar(stat = "identity", fill = "#B79477") +
coord_flip() +
xlab("Pays d'origine") +
ylab("Fréquence") +
ggtitle("Pays les plus fréquents")
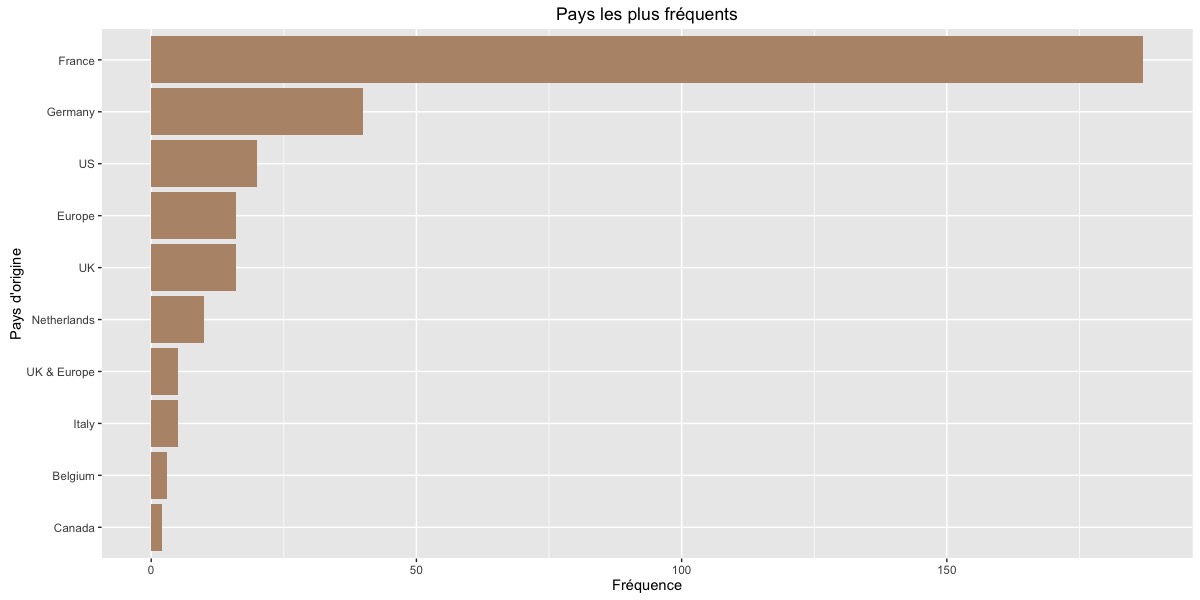 Bon, une large partie des vinyles venus de France, ça se tient :)
Bon, une large partie des vinyles venus de France, ça se tient :)
Notes moyennes des vinyles
ggplot(collection_2, aes(x = average_note)) +
geom_histogram(fill = "#B79477") +
xlab("Note moyenne") +
ylab("Fréquence") +
ggtitle("Notes moyennes des vinyles de la collection")
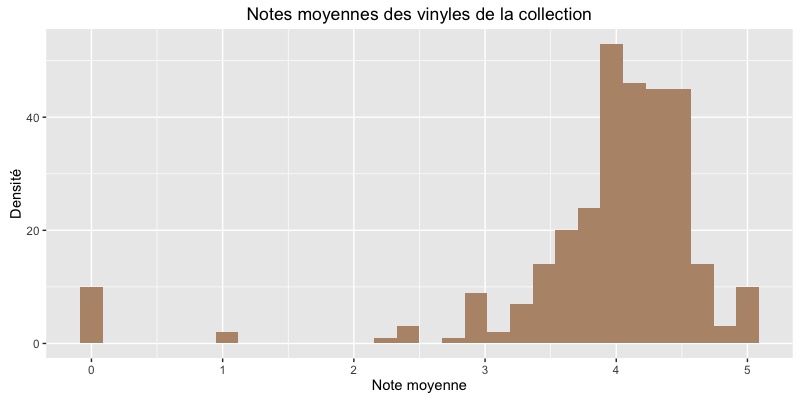
D’après la communauté Discogs j’ai plutôt de bons goûts musicaux… Merci pour cet ego boost ! (Oui, je compte ignorer la présence de 10 vinyles notés 0… Après tout, on a tous les droits à ses petits guilty pleasure…)
Money Money Money
ggplot(collection_2, aes(x = lowest_price)) +
geom_histogram(fill = "#B79477") +
xlab("Prix le plus bas") +
ylab("Fréquence") +
ggtitle("Prix le plus bas des vinyles de la collection")
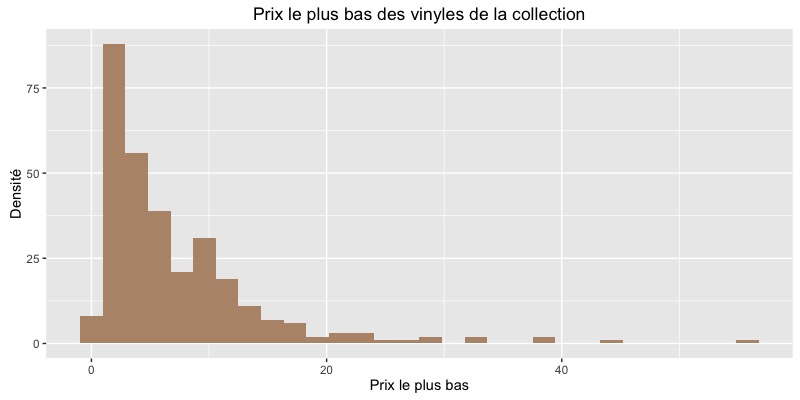
Bon… Ce n’est visiblement pas en vendant ma collection que je vais faire fortune. Cela dit, je ne comptais pas m’en séparer, cela tombe plutôt bien.
Let’s finish!
collection_complete <- merge(collection, collection_2, by = c("release_id","label", "year", "title", "artist_name"))
Prix des vinyles en fonction des “want”
lm_want <- lm(formula = lowest_price ~ want, data = collection_complete)
summary(lm_want)
##Residuals:
## Min 1Q Median 3Q Max
##-8.043 -4.628 -2.224 2.179 49.608
##Coefficients:
## Estimate Std. Error t value Pr(>|t|)
##(Intercept) 6.715418 0.450582 14.904 < 2e-16 ***
##want 0.005004 0.001788 2.799 0.00546 **
##---
##Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
##Residual standard error: 7.306 on 301 degrees of freedom
## (5 observations deleted due to missingness)
##Multiple R-squared: 0.02536, Adjusted R-squared: 0.02213
##F-statistic: 7.833 on 1 and 301 DF, p-value: 0.005461
Ici, nous voyons que le coefficient de want est significatif, avec une probabilité critique de 0.005. Nous pouvons donc conclure que, pour cette discothèque, le volume de want est significativement lié à la variable prix.
ggplot(collection_complete, aes(x = lowest_price, y = want)) +
geom_point(size = 3, color = "#B79477") +
geom_smooth(method = "lm") +
xlab("Prix le plus bas") +
ylab("Nombre de \"want\"") +
ggtitle("Prix et \"want\" des vinyles de la collection")
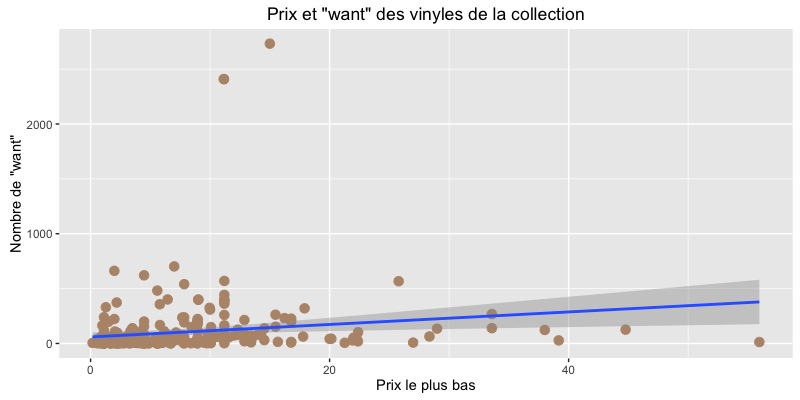
En clair : sur Discogs, il est possible d’entrer des vinyles dans une “liste d’envie”, labellisée “want” dans notre population. Ici, nous avons dessiné la régression linéaire du prix le plus bas en fonction du nombre de personnes ayant listé cette sortie dans leur liste d’envie. La tendance est légère, avec beaucoup de bruit lorsque nous nous rapprochons des prix les plus élevés.
Prix des vinyles en fonction des notes
lm_note <- lm(formula = lowest_price ~ average_note, data = collection_complete)
lm_note$coefficients
## (Intercept) average_note
## -1.504767 2.207834
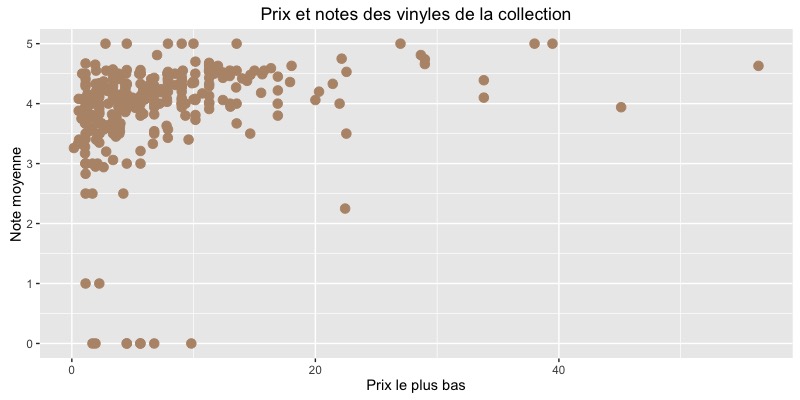
Ici, le coefficient étant de 2.2, nous ne pouvons pas lier la variable note à la variable prix. Visualisons les données pour afficher la dispersion.
ggplot(collection_complete, aes(x = lowest_price, y = average_note)) +
geom_point(size = 3, color = "#B79477") +
xlab("Prix le plus bas") +
ylab("Note moyenne") +
ylim(c(0,5)) +
ggtitle("Prix et notes des vinyles de la collection")
And to conclude…
La prochaine étape ? Faire un package pour accéder à l’API… et pourquoi pas ? Je mets ça sur ma to-do !
What do you think?