
Playing with #RStats and Microsoft Computer Vision API
Playing around with the faces of #RStats and Microsoft Computer Vision API.
This blogpost is inspired by the work of Maelle Salmon with Faces of #RStats twitter, and an article on Data Bzh using Microsoft Computer Vision API to look into old pictures of Brittany.
Microsoft Computer Vision
This API is used to retrieved description and tags for an image. Here is how you can use it with R to get information about Twitter profil pictures.
The Faces of #RStats — Automatic labelling
In this blogpost, I’ll describe how to get profil pics from Twitter, and label them with Microsoft Computer Vision.
Collecting data
library(tidyverse)
library(rtweet)
library(httr)
library(jsonlite)
token <- create_token( app = "XX", consumer_key = "XXX", consumer_secret = "XX")
users <- search_users(q= '#rstats',
n = 1000,
parse = TRUE) %>%
unique()
Note: I’ve (obviously) hidden the access token to my twitter app.
From there, I’ll use the profile_image_url column to get the url to the profile picture.
First, this variable will need some cleansing : the urls contain a _normal parameter, creating 48x48 images. The Microsoft API needs at least a 50x50 resolution, so we need to get rid of this.
users$profile_image_url <- gsub("_normal", "", users$profile_image_url)
Calling on Microsoft API
First, get a subscritpion on the Microsoft API service, and start a free trial. This free account is limited: you can only make 5,000 calls per month, and 20 per minute. But that’s far from enough for our case (478 images to look at).
users_api <- lapply(users[,25],function(i, key = "") {
request_body <- data.frame(url = i)
request_body_json <- gsub("\\[|\\]", "", toJSON(request_body, auto_unbox = "TRUE"))
result <- POST("https://api.projectoxford.ai/vision/v1.0/analyze?visualFeatures=Tags,Description,Faces,Categories",
body = request_body_json,
add_headers(.headers = c("Content-Type"="application/json","Ocp-Apim-Subscription-Key"="XXX")))
Output <- content(result)
if(length(Output$description$tags) != 0){
cap <- Output$description$captions
} else {
cap <- NA
}
if(length(Output$description$tags) !=0){
tag <-list(Output$description$tags)
}
d <- tibble(cap, tag)
Sys.sleep(time = 3)
return(d)
})%>%
do.call(rbind,.)
Note : I’ve (again) hidden my API key. _Also, this code may take a while to execute, as I’ve inserted a Sys.sleep function. To know more about the reason why, read this blogpost. _
Creating tibbles
Now I have a tibble with a column containing lists of captions & confidence, and a column with lists of the tags associated with each picture. Let’s split this.
users_cap <- lapply(users_api$cap, unlist) %>%
do.call(rbind,.) %>%
as.data.frame()
users_cap$confidence <- as.character(users_cap$confidence) %>%
as.numeric()
users_tags <- unlist(users_api$tag) %>%
data.frame(tag = .)
Visualisation
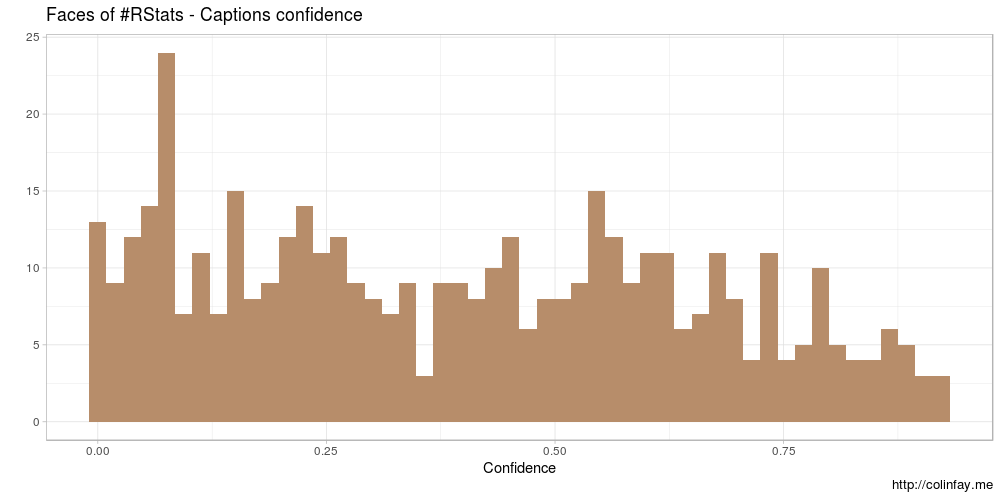
Each caption is given with a confidence score.
ggplot(users_cap, aes(as.numeric(confidence))) +
geom_histogram(fill = "#b78d6a", bins = 50) +
xlab("Confidence") +
ylab("") +
labs(title = "Faces of #RStats - Captions confidence",
caption="http://colinfay.me") +
theme_light()
Click to zoom
It seems that the confidence scores for the captions are not very strong. Well, let’s nevertheless have a look at the most frequent captions and tags.
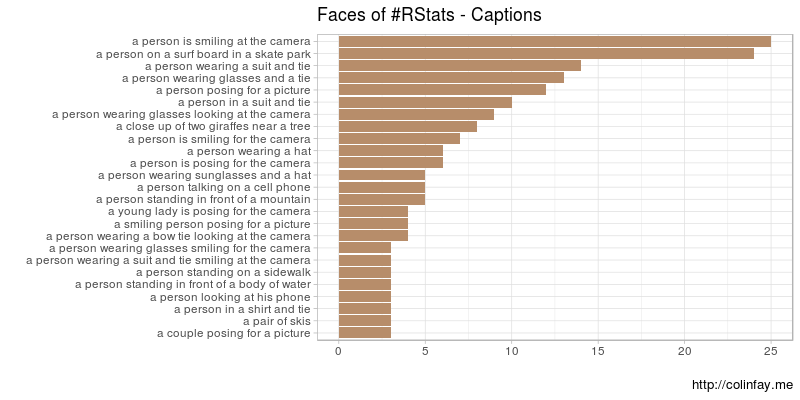
users %>%
group_by(text)%>%
summarize(somme = sum(n())) %>%
arrange(desc(somme))%>%
na.omit() %>%
.[1:25,] %>%
ggplot(aes(reorder(text, somme), somme)) +
geom_bar(stat = "identity",fill = "#b78d6a") +
coord_flip() +
xlab("") +
ylab("") +
labs(title = "Faces of #RStats - Captions",
caption="http://colinfay.me") +
theme_light()
Click to zoom
Well… I’m not sure there are so many surf and skate aficionados in the R world, but ok…
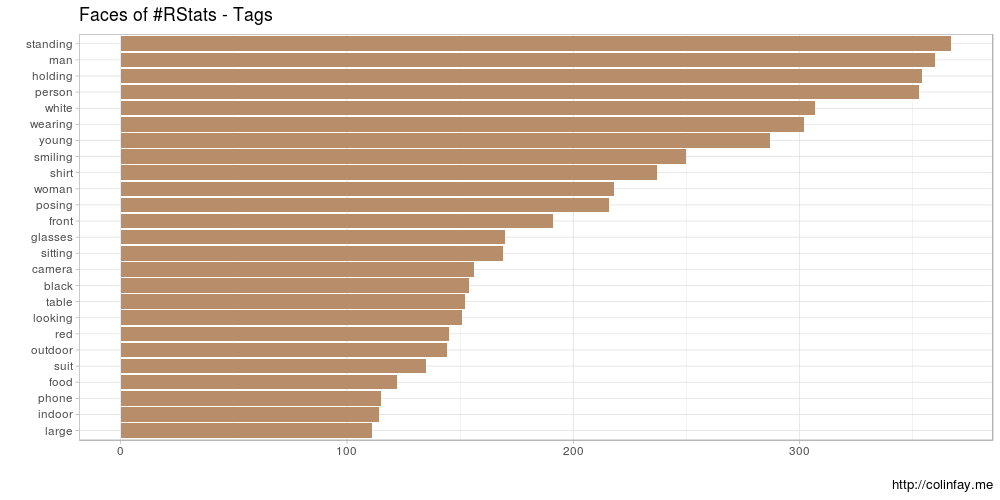
users_tags %>%
group_by(tag)%>%
summarize(somme = sum(n())) %>%
arrange(desc(somme))%>%
.[1:25,] %>%
ggplot(aes(reorder(tag, somme), somme)) +
geom_bar(stat = "identity",fill = "#b78d6a") +
coord_flip() +
xlab("") +
ylab("") +
labs(title = "Faces of #RStats - Tags",
caption="http://colinfay.me") +
theme_light()
Some checking
Let’s have a look at the picture with the highest confidence score, with the caption the API gave it.

A man wearing a suit and tie — 0.92 confidence.
He hasn’t got a tie, but the APi got it quite right for the rest.
And now, just for fun, let’s have a look at the caption with the lowest confidence score :

A close up of two giraffes near a tree - 0.02 confidence
This one is fun, so, no hard feeling Microsoft API!
On a more systemic note, let’s have a look at a collage of pictures, for the most frequent captions. _Note: in order to focus on the details of the pictures, and get rid of the genderization of the captions, I’ve replaced “man/woman/men/womens” by “person/persons” in the dataset, before making these collages. _

A person on a surf board in a skate park

A person is smiling at the camera - Confidence mean : 0.54

A close up of two giraffes near a tree — Confidence mean : 0.0037

A person wearing glasses looking at the camera
The first and third collages are clearly wrong about the captions. Yet we can see the confidence score is wery low. The second and fourth, though, seems to be more acurate. Maybe we need to try again with other pictures, just to be sure… Maybe another time ;)