
#RStats et Microsoft Computer Vision
Exploration des photos de profils des twittos #RStats avec l’API Microsoft Computer Vision.
Ce billet de blog s’inspire du travail de Maelle Salmon avec Faces of #RStats twitter et d’un article sur Data Bzh utilisant l’API Microsoft Computer Vision pour examiner d’anciennes photos de Bretagne .
Microsoft Computer Vision
Cette API est utilisée pour décrire et étiqueter automatiquement une image. Voici comment vous pouvez l’utiliser avec R, avec un jeu de données regroupant des images de profils Twitter.
Les visages #RStats — Étiquetage automatique
Dans cet article, vous trouverez un tuto sur comment obtenir des photos de profil de Twitter et les étiqueter automatiquement avec Microsoft Computer Vision.
Collecter les données
library(tidyverse)
library(rtweet)
library(httr)
library(jsonlite)
token <- create_token( app = "XX", consumer_key = "XXX", consumer_secret = "XX
users <- search_users(q= '#rstats',
n = 1000,
parse = TRUE) %>%
unique()
Note: J’ai ici anonymisé mes API keys.
Maintenant, utilisons la colonne profile_image_url pour obtenir l’url des photos de profil.
D’abord, cette variable a besoin d’être nettoyée : les URL contiennent un paramètre normal, créant des images 48x48. L’API Microsoft a besoin d’une résolution minimum de 50x50, nous devons donc nous débarrasser de ce paramètre.
users$profile_image_url <- gsub("_normal", "", users$profile_image_url)
Interroger l’API Microsoft
D’abord, inscrivez-vous sur Microsoft API service, et lancez un essai gratuit. Ce compte gratuit est limité: vous ne pouvez faire que 5 000 appels par mois et 20 par minute. Mais c’est bien assez pour notre cas (478 images à regarder).
users_api <- lapply(users[,25],function(i, key = "") {
request_body <- data.frame(url = i)
request_body_json <- gsub("\\[|\\]", "", toJSON(request_body, auto_unbox = "TRUE"))
result <- POST("https://api.projectoxford.ai/vision/v1.0/analyze?visualFeatures=Tags,Description,Faces,Categories",
body = request_body_json,
add_headers(.headers = c("Content-Type"="application/json","Ocp-Apim-Subscription-Key"="XXX")))
Output <- content(result)
if(length(Output$description$tags) != 0){
cap <- Output$description$captions
} else {
cap <- NA
}
if(length(Output$description$tags) !=0){
tag <-list(Output$description$tags)
}
d <- tibble(cap, tag)
Sys.sleep(time = 3)
return(d)
})%>%
do.call(rbind,.)
Remarque: J’ai (à nouveau) caché ma clé API. Ce code peut prendre un certain temps à exécuter, car il contient un appel à la fonction Sys.sleep. Pour en savoir plus, lire ce billet.
Créer des tibbles
Maintenant, j’ai un tibble avec une colonne contenant les listes de légendes et de score de confiance, et une colonne avec les listes des balises associées à chaque image.
users_cap <- lapply(users_api$cap, unlist) %>%
do.call(rbind,.) %>%
as.data.frame()
users_cap$confidence <- as.character(users_cap$confidence) %>%
as.numeric()
users_tags <- unlist(users_api$tag) %>%
data.frame(tag = .)
Visualisation
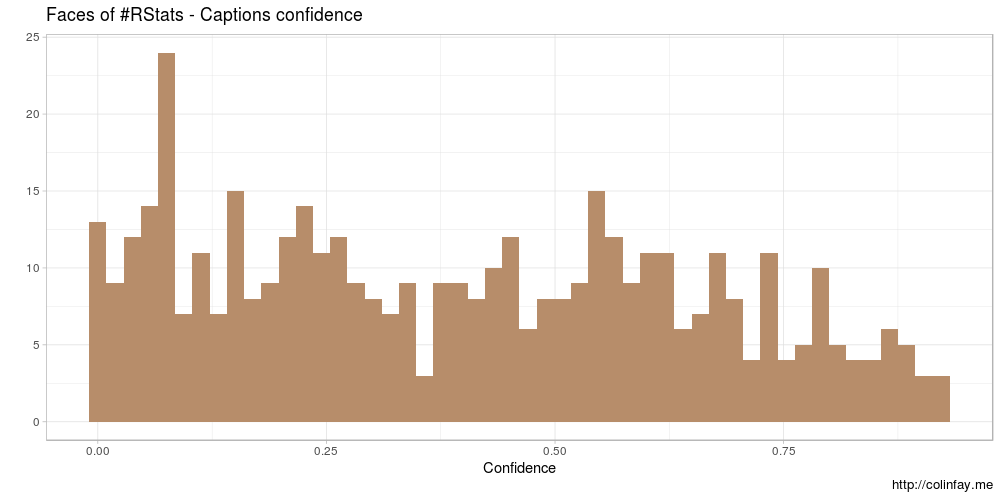
Chaque légende est donnée avec un score de confiance.
ggplot(users_cap, aes(as.numeric(confidence))) +
geom_histogram(fill = "#b78d6a", bins = 50) +
xlab("Confidence") +
ylab("") +
labs(title = "Faces of #RStats - Captions confidence",
caption="http://colinfay.me") +
theme_light()
 Cliquez pour zoomer
Cliquez pour zoomer
Il semble que les scores de confiance pour les légendes ne soient pas très forts.
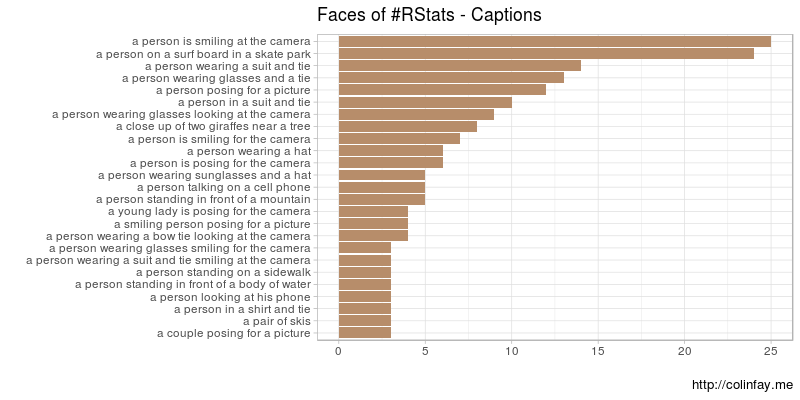
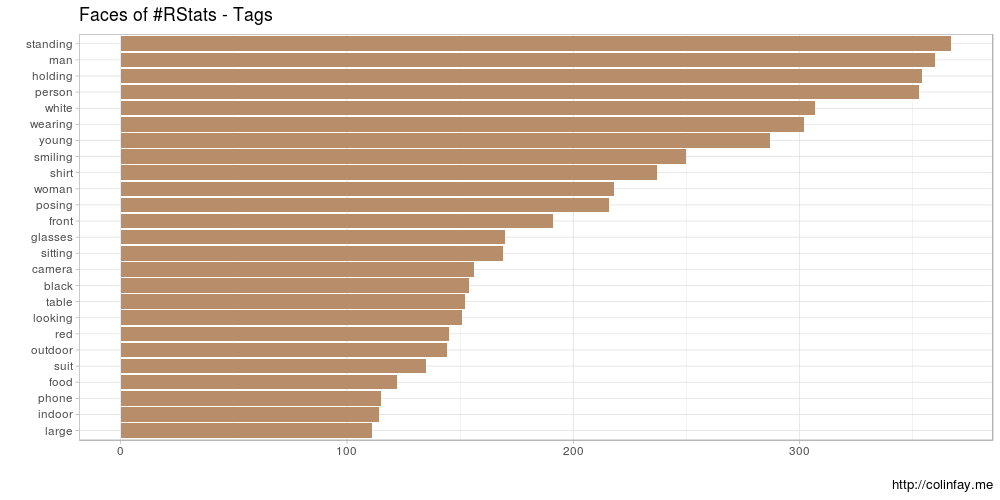
Regardons les légendes et les balises les plus fréquentes.
users %>%
group_by(text)%>%
summarize(somme = sum(n())) %>%
arrange(desc(somme))%>%
na.omit() %>%
.[1:25,] %>%
ggplot(aes(reorder(text, somme), somme)) +
geom_bar(stat = "identity",fill = "#b78d6a") +
coord_flip() +
xlab("") +
ylab("") +
labs(title = "Faces of #RStats - Captions",
caption="http://colinfay.me") +
theme_light()
 Cliquez pour zoomer
Cliquez pour zoomer
Eh bien … Je ne suis pas sûr qu’il y ait tant de passionnés de surf et de skate dans notre liste, mais soit…
users_tags %>%
group_by(tag)%>%
summarize(somme = sum(n())) %>%
arrange(desc(somme))%>%
.[1:25,] %>%
ggplot(aes(reorder(tag, somme), somme)) +
geom_bar(stat = "identity",fill = "#b78d6a") +
coord_flip() +
xlab("") +
ylab("") +
labs(title = "Faces of #RStats - Tags",
caption="http://colinfay.me") +
theme_light()
Quelques vérifications
Jetons un coup d’œil à l’image avec le score de confiance le plus élevé, avec la légende que l’API lui a donnée.

A man wearing a suit and tie — 0.92 confidence.
Il n’a pas de cravate, mais l’API a bien saisi le reste.
Et maintenant, juste pour le plaisir, la légende avec le score de confiance le plus bas :

A close up of two giraffes near a tree - 0.02 confidence
Bien vu ;)
Pour une vérification plus plus systémique, regardons un collage d’images, réalisé à partir des légendes les plus fréquentes.
_Remarque: afin de se concentrer sur les détails des images et de se débarrasser du genre des légendes, j'ai remplacé "man / woman / men / womens" par "persoe / persons" dans l'ensemble de données, avant de créer ces collages. _

A person on a surf board in a skate park

A person is smiling at the camera - Confidence mean : 0.54

A close up of two giraffes near a tree — Confidence mean : 0.0037
 A person wearing glasses looking at the camera
A person wearing glasses looking at the camera
Les premier et troisième collages sont clairement erronés sur les légendes. Mais, nous pouvons voir que le score de confiance y est très bas. Le deuxième et le quatrième, cependant, semblent être plus précis. Peut-être que nous devons essayer à nouveau avec d’autres images, juste pour être sûr … Mais ça sera pour une autre fois 😉
What do you think?